DataBase
[DATABASE] 연산자 종류
개발메모장
2025. 5. 12. 21:42
MSSQL 기준으로 작성
연산자
- 값(데이터) 또는 표현식 간의 연산(계산, 비교, 조합 등) 을 수행하는 기호 또는 키워드
- DBMS 마다 조금씩 다다르고 지원되는게 있고 안되는게 있으니 해당 DBMS에서 어떤 연산자를 제공하는지를 잘 확인하자
연산자 종류
- 산술 연산자
- 비교 연산자
- 논리 연산자
- 문자열 연산자
- NULL처리 연산자
- 집합 연산자
- 기타 특수 연산자
산술 연산자
- 숫자 데이터를 다룰 때 사용하는 기본적인 연산자들
- SELECT 문 등 계산을 직접할 수 있게 도와준다.
- 주로 숫자 컬럼이나 상수 값에 연산을 적용할 때 사용
산술 연산자 종류
| 연산자 | 의미 | 예시 | 결과 예시 |
| + | 더하기 | SELECT 100 + 100 | 200 |
| - | 빼기 | SELECT 100 - 99 | 1 |
| * | 곱하기 | SELECT 100 * 100 | 10000 |
| / | 나누기 | SELECT 10 / 5 | 2 |
| % | 나머지 | SELECT 4 % 3 | 1 |
- % 나머지 연산자는 DBMS 마다 지원 여부가 다르기 때문에 잘 확인해야한다.
비교 연산자
- 비교 연산자는 값을 비교할 때 사용한다.
- WHERE절, CASE문, IF문 등에서 자주 사용되고 참(True)/거짓(False) 결과를 반환
비교 연산자 종류
| 연산자 | 의미 | 예시 | 설명 |
| = | 같다 | AGE = 30 | 나이가 30과 같은지 |
| != 또는 <> | 같지 않다 | AGE != 30, AGE <> 30 | 나이가 30이 아닌 |
| >, < | 크다(초과), 작다(미만) | AGE > 30, AGE < 30 | 30보다 큰 나이, 30보다 작은 나이 |
| >=, <= | 크거나 같다(이상), 작거나 같다(이하) | AGE >= 30, AGE <= 30 | 나이가 30 이상, 나이가 30 이하 |
| BETWEEN A AND B | A 이상 B 이하 | AGE BETWEEN 20 AND 30 | 나이가 20 이상 부터 30 이하 |
| IN (...) | 목록에 포함 | AGE IN (20, 30) | 나이가 20, 30과 같은 |
| NOT IN (...) | 목록에 미포함 | AGE NOT IN (20, 30) | 나이가 20, 30과 같지 않은 |
논리 연산자
- 여러 조건을 결합하거나 부정할 때 사용
- WHERE 절, HAVING 절, CASE 문, IF 문 등에서 사용
논리 연산자 종류
| 연산자 | 의미 | 예시 | 설명 |
| AND | 그리고 (모두 참) | AGE >= 20 AND AGE <= 30 | 20이상이면서 30세 이하 |
| OR | 또는 (하나라도 참) | CITY = '서울' OR CITY = '부산' | 도시가 서울이거나 부산 |
| NOT | 부정 (반대로) | NOT CITY = '서울' | 서울이 아닌 도시 |
논리 연산자의 우선순위
- NOT
- AND
- OR
- 괄호를 () 사용해 명확하게 조건을 그룹화하는게 안전하다.
- WHERE A AND B OR C 이런 식으로 쓰면 위험할 수 있다. => WHERE A AND (B OR C) 처럼 괄호를 사용
문자열 연산자
- 문자열을 비교, 검색, 연결, 포함 여부 확인할 때 사용하는 연산자
문자열 연산자 종류
| 연산자 | 의미 | 예시 | 설명 |
| + | 문자열 연결 | '강' + '호' + '동' | 문자열 연결 |
| LIKE | 문자열 패턴 일치 | NAME LIKE '%호동%' | 이름에 '호동'이 포함되어 있는지 |
| NOT LIKE | 문자열 패턴 불일치 | NAME NOT LIKE '%호동%' | 이름에 '호동'이 포함되지 않은 |
- LIKE문 같은 경우 '%' 기준으로 패턴이 달라진다. ('%' 를 와일드 카드라고 부른다.)
- LIKE '문자%' : 문자로 시작하는 / 예) LIKE '강%' => '강' 으로 시작하는
- LIKE '%문자' : 문자로 끝나는 / 예) LIKE '%호동' => '호동' 으로 끝나는
- LIKE '%문자%' : 문자가 포함된 / 예) LIKE '%호동%' => '호동' 이 포함된
NULL처리 연산자
- NULL(값 없음) 여부를 검사
NULL처리 연산자 종류
| 연산자 | 의미 | 예시 | 설명 |
| IS NULL | NULL 인지? | ADDRESS IS NULL | 주소가 NULL 값인 |
| IS NOT NULL | NULL 아닌지? | ADDRESS IS NOT NULL | 주소가 NULL 값이 아닌 |
집합 연산자
- 서로 다른 SELECT 결과를 병합하거나 비교할 때 사용
- 집합 연산자의 주의점은 작성시 서로 컬럼 갯수가 동일해야한다.
- 가급적이면 별칭은 컬럼끼리 통일시켜 맞추는게 좋다
집합 연산자 종류
| 연산자 | 의미 | 예시 | 설명 |
| UNION | 합집합 (중복 데이터 제거) | SELECT NAME FROM A UNION SELECT NAME FROM B |
A와 B의 결과를 합치되 중복 제거한 값 |
| UNION ALL | 합집합 (중복 데이터 포함) | SELECT NAME FROM A UNION ALL SELECT NAME FROM B |
A와 B의 결과를 합한 모든 값(중복 포함) |
| INTERSECT | 교집합 | SELECT NAME FROM A INTERSECT SELECT NAEM FROM B |
A와 B 둘 다 있는 값 |
| EXCEPT | 차집합 | SELECT NAME FROM A EXCEPT SELECT NAME FROM B |
A에는 있지만 B에는 없는 값 |
집합 연산자 예시
예시 테이블

UNION
- UNION으로 직원과 인턴 테이블의 이름을 한 테이블로 출력하고 싶다.
- UNION은 중복데이터가 제거된다.
- 예상되는 데이터는 이름이 겹치는 '홍길동', '김영희' 는 두 번 나오는게 아니라 한 번씩만 나온다.
결과

쿼리문
SELECT EMP_NM AS NAME
FROM EMPLOYEES
UNION
SELECT INTERNS_NM AS NAME
FROM INTERNSUNION ALL
- UNION ALL 로 직원과 인턴 테이블의 이름을 한 테이블로 출력하고 싶다.
- UNION ALL 은 중복데이터를 제거하는 UNION과는 달리 모든 데이터를 포함시킨다.
- 예상되는 데이터는 각각 테이블 5명 + 5명 해서 총 10개의 데이터가 출력된다.
결과

쿼리문
SELECT EMP_NM AS NAME
FROM EMPLOYEES
UNION ALL
SELECT INTERNS_NM AS NAME
FROM INTERNSINTERSECT
- INTERSECT은 교집합이다.
- 서로 중복되는 데이터를 출력해주기 때문에 예상되는 데이터는 두 테이블에서 같은 데이터를 가진 '홍길동', '김영희'이다.
결과

쿼리문
SELECT EMP_NM AS NAME
FROM EMPLOYEES
INTERSECT
SELECT INTERNS_NM AS NAME
FROM INTERNSEXCEPT
- EXCEPT 는 차집합이다.
- A 테이블에는 있지만 B에는 없는 값
- 즉 직원(EMPLOYEES) 테이블에는 있지만 인턴(INTERS) 테이블에 없는 값
- '홍길동', '김영희' 는 직원 테이블과 인턴 테이블에 둘다 있고
- 직원 테이블에 '이철수', '박민수', '최유리'는 직원 테이블에만 있고 인턴 테이블에는 없기 때문에 저 3명의 이름이 출력된다.
결과

쿼리문
SELECT EMP_NM AS NAME
FROM EMPLOYEES
EXCEPT
SELECT INTERNS_NM AS NAME
FROM INTERNS기타 특수 연산자
- 특정 상황에서 사용되는 연산자
기타 특수 연산자의 종류
| 연산자 | 의미 |
| EXISTS | 서브쿼리 결과가 존재할 경우 TRUE |
| NOT EXISTS | 서브쿼리 결과가 없는 경우 TRUE |
| ALL | 서브쿼리 결과과 모두 조건을 만족하면 TRUE |
| ANY | 서브쿼리 결과 중 하나라도 조건을 만족하면 TRUE |
기타 특수 연산자 예시
예시 테이블

EXISTS
- 서브쿼리 결과가 존재할 경우 TRUE를 반환한다.
- 그럼 직원 테이블에서 인턴 테이블의 급여(SALARY)가 같은 직원들을 조회하고 싶다.
- 직원 테이블에 '김영희' (3000), '최유리' (2000)이 인턴 테이블에 '유재석' (3000), '박병수' (2000)과 급여가 일치한다.
- 예상되는 데이터는 '김영희', '최유리' 가 출력된다.
결과

쿼리문
SELECT
E.EMP_NM AS '직원',
E.SALARY AS '급여'
FROM EMPLOYEES E
WHERE EXISTS (
SELECT I.SALARY
FROM INTERNS I
WHERE I.SALARY = E.SALARY
)NOT EXISTS
- 서브쿼리 결과가 없는 경우 TRUE를 반환한다.
- 그럼 반대로 직원 테이블의 급여와 인턴 테이블의 급여가 서로 맞지 않은 직원을 조회하고 싶다.
- 예상되는 데이터는 '홍길동' (4000), '이철수' (5000), '박민수' (6000) 이다.
결과

쿼리문
SELECT
E.EMP_NM AS '직원',
E.SALARY AS '급여'
FROM EMPLOYEES E
WHERE NOT EXISTS (
SELECT I.SALARY
FROM INTERNS I
WHERE I.SALARY = E.SALARY
)ALL
- 서브쿼리 결과가 모두 만족하는 경우 TRUE를 반환한다.
- 직원들 중 인턴 급여 보다 높은 직원들 보고 싶다.
- 인턴 테이블에서 제일 높은 급여는 '유재석' (3000)이다.
- 직원들 중 3000을 넘는 급여를 가진 직원은 '홍길동' (4000), '이철수' (5000), '박민수' (6000) 이다.
결과

쿼리문
SELECT E.EMP_NM, E.SALARY
FROM Employees E
WHERE E.SALARY > ALL (
SELECT SALARY FROM Interns
);ANY
- 서브쿼리 결과중 하나라도 조건에 맞으면 TRUE를 반환한다.
- 직원들 중에서 인턴과 비교했을 때 인턴보다 낮은 직원이 있는지 보고싶다.
- 인턴 테이블 최고 급여자는 '유재석' (3000)이다.
- 직원 테이블에서 '유재석' (3000) 보다 낮은 직원은 '최유리' (2000)이다.
결과
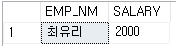
쿼리문
SELECT E.EMP_NM, E.SALARY
FROM Employees E
WHERE E.SALARY < ANY (
SELECT SALARY FROM Interns
);